The OpenSpending Revamp: Behind the Scenes

Luccas Mateus

João Demenech
This post was originally published on the Datopian blog.
In our last article, we explored the Open Spending revamp. Now, let's dive into the tech stack that makes it tick. We'll unpack how PortalJS, Cloudflare R2, Frictionless Data Packages, and Octokit come together to power this next-level data portal. From our Javascript framework PortalJS, that shapes the user experience, to Cloudflare R2, the robust storage solution that secures the data, we'll examine how each piece of technology contributes to the bigger picture. We'll also delve into the roles of Frictionless Data Packages for metadata management and Octokit for automating dataset metadata retrieval. Read on for the inside scoop!
The Core: PortalJS
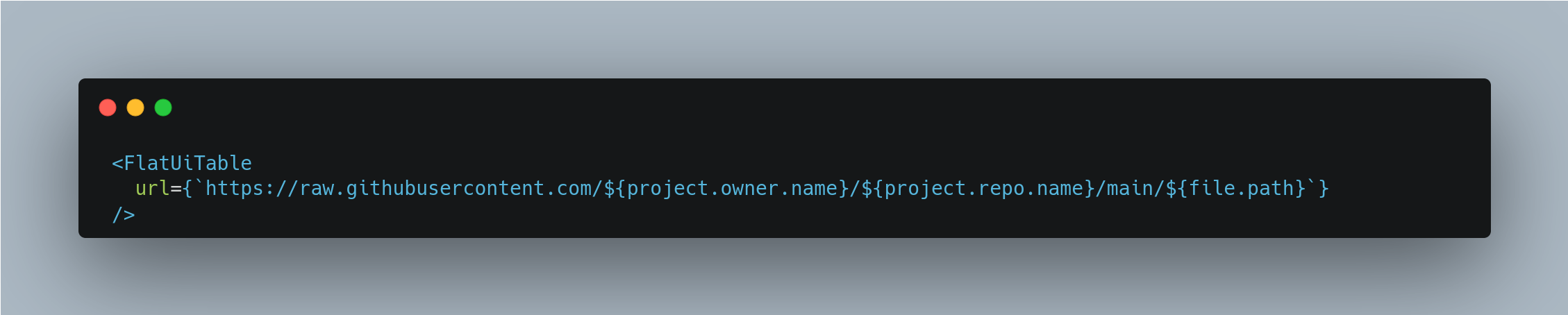
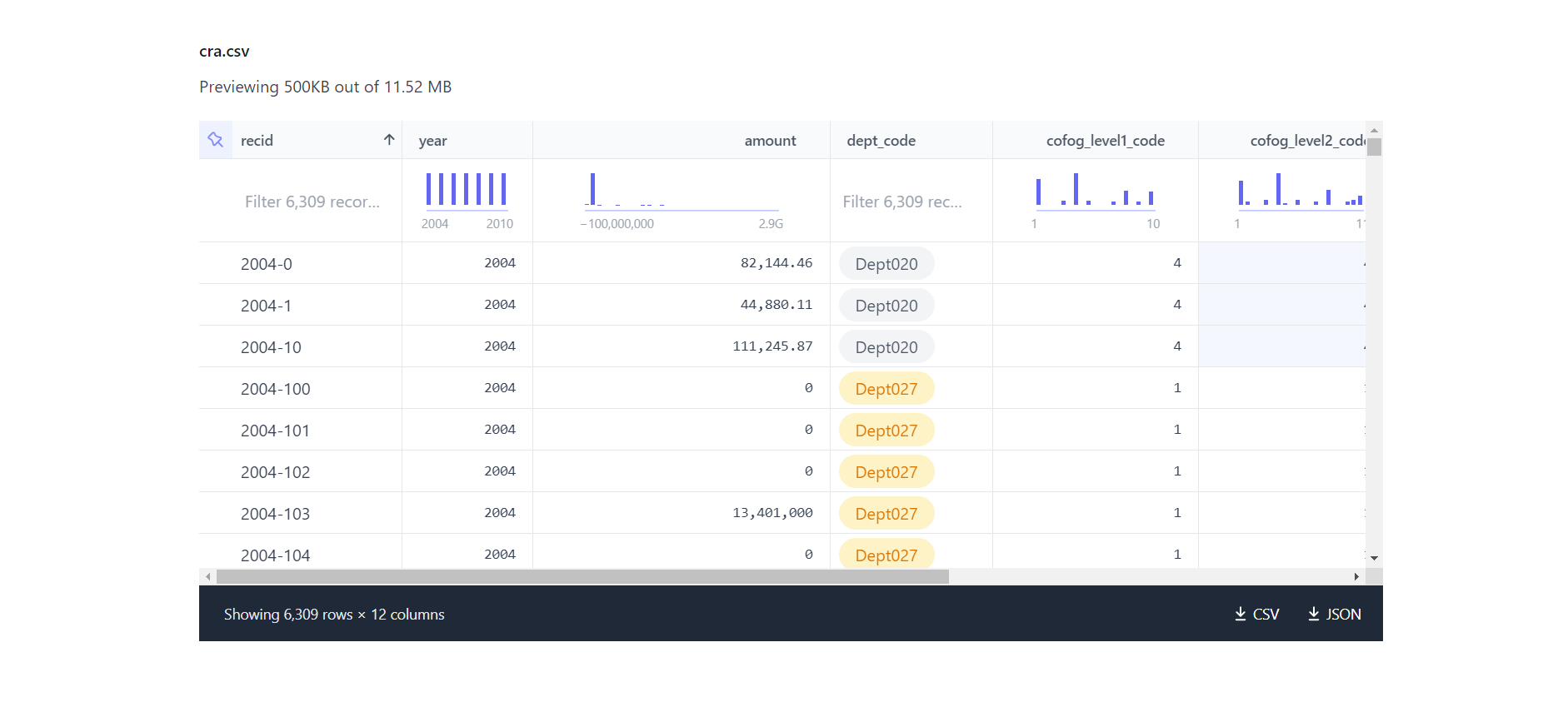
At the core of the revamped OpenSpending website is PortalJS, a JavaScript library that's a game-changer in building powerful data portals with data visualizations. What makes it so special? Well, it's packed with reusable React components that make our lives - and yours - a whole lot easier. Take, for example, our sleek CSV previews; they're brought to life by PortalJS' FlatUI Component. It helps transform raw numbers into visuals that you can easily understand and use. Curious to know more? Check out the official PortalJS website.
Metadata: Frictionless Data Packages
Storing metadata might seem like a backstage operation, but it is pivotal. We chose Frictionless Data Packages, housed in the os-data GitHub organization as repositories, to serve this purpose. Frictionless Data Packages offer a simple but powerful format for cataloging and packaging a collection of data - in our scenario, that's primarily tabular data. These aren't merely storage bins - they align with FAIR principles, ensuring that the data is easily Findable, Accessible, Interoperable, and Reusable. This alignment positions them as an ideal solution for publishing datasets designed to be both openly accessible and highly usable. Learn more from their official documentation.
The Link: Octokit
Can you imagine having to manually gather metadata for each dataset from multiple GitHub repositories? Sounds tedious, right? That’s why we used Octokit, a GitHub API client for Node.js. This tool takes care of the heavy lifting, automating the metadata retrieval process for us. If you're intrigued by Octokit's capabilities, you can discover more in its GitHub repository. To explore the datasets we've been working on, take a look at OpenSpending Datasets.
Storage: Cloudflare R2
When it comes to data storage, Cloudflare R2 emerges as our choice, defined by its blend of speed and reliability. This service empowers developers to securely store large amounts of blob data without the costly egress bandwidth fees associated with typical cloud storage services. For a comprehensive understanding of Cloudflare R2, their blog post serves as an excellent resource.
In Closing
In closing, we invite you to explore the architecture and code that power this project. It's all openly accessible in our GitHub repository. Should you want to experience the end result firsthand, feel free to visit openspending.org. If you encounter any issues or have suggestions to improve the project, we welcome your contributions via our GitHub issues page. For real-time assistance and to engage with our community, don't hesitate to join our Discord Channel. Thank you for taking the time to read about our work! We look forward to fostering a collaborative environment where knowledge is freely shared and continually enriched. ♥️